

Resolving AI's Bad Hallucination Trip
Private instances and better data management create improvements for enterprises.


Image created on Midjourney.
An auto dealer answer engine delivers an incorrect pricing response, offering a $58,000 Chevy for $1. It's a bad trip for every business, but every day this occurs over and over again to lesser degrees when users engage with LLMs. No one wants their branded AI to have a "hallucination issue" that occurs when LLMs generate inaccurate or fabricated information.
LLM hallucination is a significant barrier to widespread adoption in enterprise applications, and with good reason. Financial welfare and brand reputation are at risk.
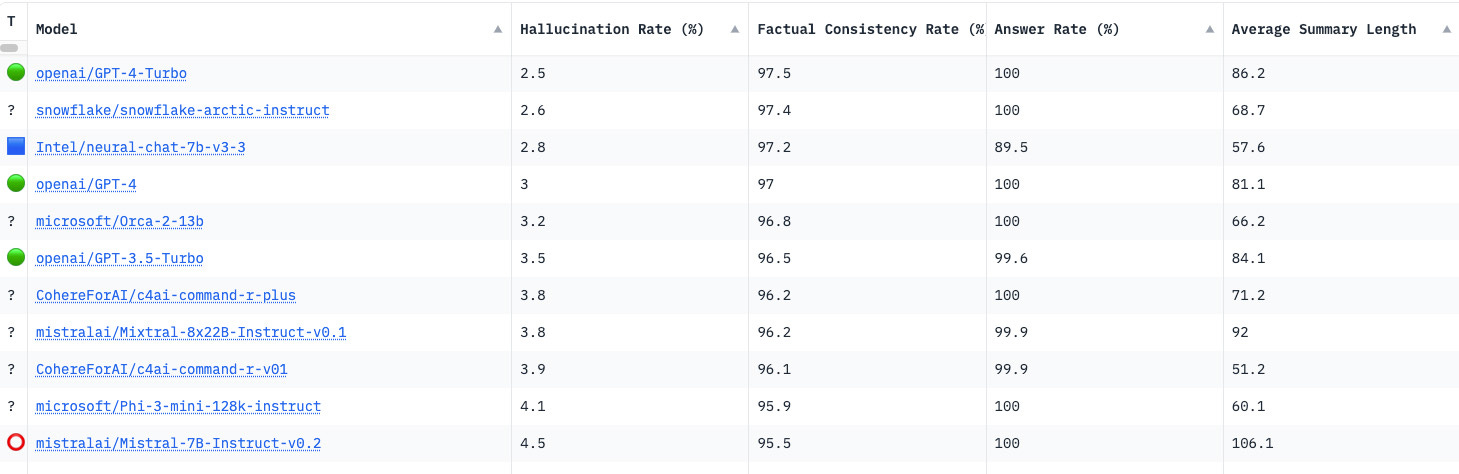
The issue isn't going away quickly. Much to the chagrin of LLM developers, even the most recent releases of GPT 4 Turbo, Claude 3, Cohere, Gemini, and Llama still hallucinate. The current Hugging Face Hallucination Index demonstrates a continued challenge. Even in the best cases, public LLMs are hallucinating at a 1 in 25 rate.
Foundational Logic and Data Problems

Are some databases as filled with garbage as landfills? Image captured by me at the Trans-Jordan landfill in Utah.
While the above accuracy rates are worthy of As in school and better than human responses, LLMs have a fundamental logic problem. Like every other form of AI, generative AI solutions focus on probability to provide the best answer possible. That means they rely on their training data to inform their answer, which means if source information is incorrect or incomplete, the LLM serves a response that's not accurate.
So, as the old AI adage goes, "garbage in, garbage out." Better hope your LLM wasn't trained on X posts.
One standard answer is to source links to source data, such as Perplexity and Google's Gemini. However, even though source data is referred to, the public information may not be correct. Worse, Internet users may not be literate enough to delineate the AI's response or the source information's accuracy.
Then, contextual challenges remain. An LLM trained on general public data may need help understanding a specific industry or profession's domain knowledge. If additional training is not provided to the algorithm, it cannot understand the source data. The LLM will use probability to guess the best correct answer, e.g., it hallucinates. Incomplete source data also yields hallucinations.
RAG Databases to the Rescue?
Almost every solution that addresses the hallucination issue revolves around creating more control over the AI's response, ensuring it stays within set guardrails. That begins by locking down the sources for answers with a retrieval augmented generation (RAG) database in a private implementation.
Private instances allow companies and organizations to build applications tailored to their specific needs, utilizing their own data while maintaining security and governance over the information. In such cases, an enterprise will create an LLM housed on its private cloud and select some of its private datasets to inform the answer engine's responses.

Effectively training the LLM algorithm to answer within a specific dataset, RAG combats GenAI hallucinations by providing the "factual" grounding. RAG uses specified private data sources for relevant information to supplement the LLM's public knowledge – and can be forced to anchor its responses in that actual data, reducing the risk of fabricated or whimsical outputs.
However, RAG is not a silver bullet solution. The LLM's algorithm, specifically its programmed logic, can still create its own answers if it cannot resolve the question. Both the algorithm's inability to understand the industry-specific context and incomplete and unclean enterprise data are primary drivers of RAG hallucinations.
Better Answers Come from Cleaner Data
Neil Katz, CEO of EyeLevel.ai, shared his insights on his company's primary focus of solving the hallucination issue in our most recent No Brainer Podcast. Katz emphasized the importance of private instances for organizations instead of licensing pre-built tools like ChatGPT or Claude.
Implementing LLMs with answers better than standard RAG quality will force enterprises to address their need for more data governance for structured data and unstructured content. Many organizations have their information stored in various formats, such as PDFs, PowerPoints, and web pages, which LLMs cannot easily process, said Katz in our conversation.
Data cleaning and enrichment still play a role in better answers. EyeLevel.ai has developed an API tool to address this issue by breaking down and transforming these complex documents into a format LLMs can understand, thereby reducing the hallucination problem and achieving greater accuracy rates.
This is particularly needed with unstructured content forms such as web content and PDFs often used to feed private instances. Some call this effort pre-retrieval optimization of their content, but it really means cleaning up typos, adding metadata and structure, and verifying data accuracy.
Another approach used by companies like Writer and Eyelevel is better knowledge graphing or indexing of data in consumable "chunks" or data pieces to better inform the LLM. Some solution providers use natural language processing (NLP) algorithms to prepare unstructured data for ingestion in a RAG database.
In the end, enterprises need to face the data governance music when it comes to AI. Business AI problems are usually data problems.
It is critical to implement processes to ensure new data and written and visual content are better structured to meet AI's needs. At some point, support algorithms will clean data for humans and this will be a non-issue. But in our current state, this is a supporting solution, not a stand-alone AI.
One thing is clear: while improvements are happening, the sector has yet to lock down hallucinations with confidence. Humans are still needed to check answers. In the immediate future, digital literacy requires a fact check of any LLM-fueled response, and even in the most accurate instances, enterprises using LLMs will still need a clearly stated legal disclaimer about the engine's answers to protect the brand.
After We Resolve the Hallucination Issue…
Neil Katz on the future of AI.
Addressing key challenges like data accuracy and hallucination is necessary to pave the way for the successful implementation of these technologies in enterprise settings. While the sector wants to move onto "AGI" or artificial general intelligence algorithms, its clear answer and response accuracy must improve first.
What happens after that is the stuff of dreams. We can imagine great things of AI… once we can trust the integrity of its responses. At a minimum, answer engines become a much more powerful tool for the enterprise.
Looking towards the future, Katz told us that we are just at the beginning of the AI race. He foresees the potential for LLMs to expand beyond language processing and into hard sciences, such as engineering, mathematics, and physics. This could lead to exponential advancements in space exploration, medicine, and architecture.
Additionally, integrating LLMs with robotics could revolutionize how we interact with machines, creating a more intuitive and natural interface. However, Katz acknowledged there are still challenges to overcome, such as developing new architectures and increasing computational power to support these advancements.
However you and your company envision AI playing out, keep your eye on the ball. Ultimately, successful use of brand-specific generative AI text solutions, more often than not, requires a private LLM implementation with an RAG or similar approach to sourcing answers and strong data preparation.
Related Reading
Does AGI Really Matter or Just More Hype?

Artificial general intelligence or AGI will arrive within five years, says AI industry marketing engines at NVIDIA, OpenAI, and others. Should enterprise executives care, or is this another hype distraction? The TLDR version: Pass, AGI is hype and won’t impact the enterprise anytime soon.
Future of Marketing: Content Becomes More Valuable

This is the final article in our Future of Marketing series. Image created on Midjourney. Much has been said about AI lowering the quality of content on the Internet. That trend will continue, making original content much more valuable. In this new reality, content is unstructured data, and that data is gold.